Bank marketing 정기예금 가입여부 예측
#randomforest #XGB #machinelearning
목차
- Time seriesAnomaly Detection Generative Adversarial Networks-Model Structure
- Time seriesAnomaly Detection Generative Adversarial Networks-loss function
- Intro to the Time Series Anomaly Detection
- Text 데이터 광고 필터링을 위한 분류 모델 구축
- 사용자 리뷰 핵심어 추출 및 감성분석
- Deep Learning - 핵심 개념 & 용어
- NLP - 딥러닝 모델의 범용적 활용가능성 분석
- Bank marketing 정기예금 가입여부 예측
- ROC curve에 대해 알아보자
- 연어의 회귀본능이 아닌 선형회귀에 대해 알아보자
Section 2 Project - Bank marketing 정기예금 가입여부 예측하기
abstract
- 이윤을 추구하는 기업의 입장에서는 최소한으로 투자하고 최대한의 효과를 보기위해 부단히 노력하기 마련이다. 때문에 자사의 제품이나 서비스에 대한 마케팅을 실시할 때도 불필요한 지출은 줄이고 꼭 필요한 비용만을 이용하여 최대효율을 달성하는 것을 지향한다.
본 프로젝트는 은행에서 정기예금에 대한 마케팅을 실시할 때, 무작위로 대상을 선정하기보다 정기예금을 신청할 것 같은 대상을 효율적으로 분별하여 마케팅을 실시할 수 있도록 한다. 핀포인트 마케팅이 가능하도록 하는 예측모델을 만들어보고 이를 개선시키는 것을 목적으로 진행하였다.
1. 시나리오
포르투갈의 한 은행에서 새롭게 출시하는 정기예금 상품을 기존 고객들을 대상으로 영업을 할 계획을 세우고 있다.
기존에는 무작위로 대상을 선별하여 연락하는 방법을 고수하였으나 이때 임시로 텔레마케터를 고용하는데 드는 비용이나
마케팅에 성실하게 응답하는 고객이 많이 없다는 점이 문제로 지적된다. 그래서 이 문제를 해결하기 위해
은행에서 수집한 고객 데이터를 바탕으로 마케팅이 성공할 수 있을지 여부를 분류해주는 예측모델을 만들어달라고 의뢰하였다.
이렇게 우리는 제공받은 고객데이터를 바탕으로 "정기예금 신청여부"를 예측해주는 모델을 제작하게 되는데...
1.1 제공받은 데이터
bank client data: (은행 고객관련 특성)
- 나이
- 직업
- 결혼 여부
- 교육수준
- 채무불이행 여부
- 주택 담보 대출 여부
- 개인 대출 여부
related with the last contact of the current campaign: (현재 캠페인의 마지막 연락 관련 특성)
- 접촉 수단
- 마지막 연락(월)
- 마지막 연락(요일)
- 마지막 접촉 기간(초) : leakage 주의
other attributes: (기타 특성)
- 캠페인 중 고객에게 연락한 횟수
- 이전 캠페인에서 고객과 마지막으로 연락 후 경과일
- 캠페인 이전 고객에게 연락횟수
- 이전 마케팅 캠페인 결과
social and economic context attributes(사회, 경제적 특성)
- 고용 변동률-분기별
- 소비자 물가지수-월별
- 소비자 신뢰지수
- Euribo(유럽연합 내 12개국 시중은행간 금리)
- 직원 수(분기)
- 정기예금 신청 여부
1.2 예측모델 정의

내가 만들게 될 모델은 데이터를 입력받았을 때 정기예금 신청여부를 “예”, “아니오”로 대답하는 이진분류 모델이 될 것이고 예측모델의 타겟이 되는 정기예금 신청여부를 확인해본 결과 yes와 no가 약 1:9 의 비율로 상당히 불균형한 것을 알 수 있다. 이런 경우, 전부 ‘no’로 예측해도 정확도가 90%에 가깝기 때문에 정확도를 지표로 삼기보다 다른 평가지표를 활용해야 할 것이다. accuracy나 confusion matrix의 경우는 클래스불균형 문제에서 퍼포먼스를 왜곡할 가능성이 있다는 연구결과를 보게되었고 이때 추천할 수 있는 방법으로 클래스 불균형 여부에 상관없이 일정한 퍼포먼스 인덱스를 제공해주는 AUC, F1-score 두 가지를 평가에 활용할 예정이다. 또한 평가방법으로는 Cross validation을 선택하였는데 이는 전체적인 데이터셋의 크기가 크지 않다고 판단했기 때문이다.
2. EDA
데이터는 상당히 잘 정제되어있는 상태였으며 간단한 전처리과정을 거치고 바로 EDA 작업에 들어갔다. 가장 먼저 각각의 개별적인 특성에 따라 정기예금 신청여부를 얼마나 잘 구별할 수 있는지 알아보기위해 특성별 타겟분포를 시각화해본 결과 중에 타겟의 분포에 따라 뚜렷한 차이를 보여 타겟 예측에 도움을 줄 것 같은 특성들과 별로 차이가 없어 별 도움을 줄 것같지 않은 특성을 몇가지 소개한다. 먼저 이전의 마케팅 결과에 대한 특성이 존재하여 예측에 큰 힘을 싣어줄 것으로 기대했으나

분포를 살펴본 결과 대부분 데이터가 없는 것으로 볼 때, 이전의 마케팅에 참여한 적이 없는 신규고객들이 대다수인 것을 알 수 있었다.
마지막 접촉(월)에 따른 타겟 분포를 살펴보면

5,6,7,8월 같은 특정 월에 집중적으로 가입자 수가 많은 것을 알 수 있다.
결혼 여부에 따른 타겟 분포를 살펴보면,

결혼상태에 따라서 정기예금 신청여부도 기혼, 미혼, 이혼 상태 등의 순서로 예금 가입여부가 차이가 난다는 것을 볼 수 있다.
반면 나이에 따른 타겟분포를 살펴보면,

정기예금을 신청한 경우와 그렇지 않은 경우 모두 평균연령이 비슷한 30대 후반인 것을 알 수 있었다. 따라서 이 특성은 타겟을 분류하는데 별로 좋은 특성이 아닐 것이라고 생각했다.
마지막 접촉(요일) 특성 또한

특정 요일에 편향되지 않고 고르게 타겟의 분포가 형성되어 있는 것을 보면 타겟을 분류하는데 좋은 특성이 아니라고 추측할 수 있다.


소비자 신뢰지수나 유럽 시중은행의 금리 지수(euribo) 에 따른 타겟의 분포도 차이가 있어 EDA단계에서 의미를 찾지는 못했으나 예측모델을 만드는데 긍정적인 역할을 할 수 있을 것이라고 생각되었다.
3. 모델링
모델링은 작업은
- 좋은 성능을 보여주는 앙상블 모델 중
- bagging모델의 대표주자 랜덤포레스트분류모델(이하 RF)과 boosting모델의 대표주자 그레디언트부스팅(이하 XGB) 분류모델 두가지를 비교하여
- 더 좋은 성능을 보여주는 모델 한가지를 선택한 후 성능개선
순서로 진행하였다. 먼저 RF 모델과 XGB 모델을 동일하게 랜덤서치CV를 통하여 최적파라미터를 찾아준 다음 성능을 파악한 결과
RF
auc : 0.778
f1 : 0.353
XGB
auc : 0.804
f1 : 0.366
XGB 모델이 모든 성능지표에서 성능상 우위를 가지는 것을 볼 수 있었다. 이렇게 예측모델의 기법은 XGB모델로 결정하고 성능개선 작업을 시작했다.
3.1 성능개선
XGB 모델은 RF모델보다 하이퍼파라미터의 튜닝에 민감하게 반응하는 모델기법이다. 그래서 큰 기대를 가지고 모델성능 개선작업에 착수하였다.
성능개선 작업은
- 특성의 특징에 따라 인코딩 방법을 섞어서 진행
- 타겟의 클래스를 비슷하게 보정 두 단계로 진행해보았다.
먼저 인코딩방법은 기존에는 사용해봤을 때 무난한 성능을 보여주었던 ordinal 인코더를 사용했었다. 하지만 새로 인코딩을 실시할 때는, 범주가 적고 범주간에 우선순위가 없는 특성에는 OneHotEncoder를 사용하였고 그 외의 특성에는 TargetEncoder를 사용하여 성능을 향상시키려고 시도하였다. 인코딩 작업이 완료된 후의 성능은
XGB
auc : 0.807
f1 : 0.375
으로 소폭의 성능향상이 이루어졌다.
두번째로 성능을 향상시키는 아이디어는 오버샘플링으로 모든 예측모델은 타겟의 클래스가 50:50일 때 가장 성능이 좋다는 점에 착안한 방법이다. 이 방법에도 언더샘플링과 오버샘플링 두가지 방법이 있으나 언더샘플링은 데이터양이 줄어들기 때문에 학습 시 실행시간을 줄일 수 있다는 장점이 있지만 분류모델을 만들 때 유용하게 사용될 수 있는 데이터가 유실될 우려가 있고 임의적으로 뽑은 샘플이 편향되거나 모집단을 대표하지 않을 수 있어 최종적으로 테스트셋에 적용했을 때 결과가 좋지 않을 수 있다.
오버샘플링은 소수클래스를 임의로 복제하여 수를 늘리는 방법인데 소수 클래스를 판별할 때 과적합의 우려가 있으나 전반적으로 언더샘플링보다 뛰어난 효과를 보여주므로 오버샘플링 기법으로 클래스의 비율을 맞출 것이다. 이 중에서도 Synthetic Minority Over-sampling Technique (SMOTE) 알고리즘은 소수클래스로부터 일부를 선택하여 인접한 데이터 샘플을 찾아 그 사이에 새로운 데이터를 생성하는 방법으로 임의로 오버샘플링을 했을 때보다 과적합을 완화시킬 수 있다.
따라서 오버샘플링 중에 SMOTE라는 방법으로 오버샘플링을 진행하였다.
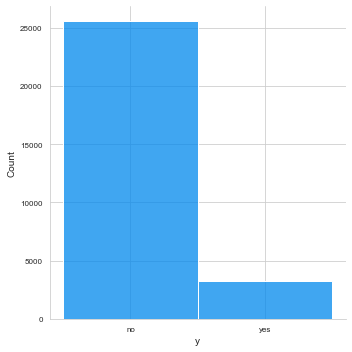

좌측은 샘플링을 실시하기 전, 우측은 샘플링을 실시한 이후의 클래스 분포를 보여준다.
샘플링 이후의 데이터로 다시 모델을 돌렸을 때의 성능은
XGB
auc : 0.976
f1 : 0.898
auc 스코어와 f1스코어 모두 대폭 성능이 향상된 것을 볼 수 있었고 모델의 클래스 분포에 따라 같은 모델이라도 입력되는 학습데이터셋에 따라서 성능차이가 나는지를 확인할 수 있었다.
4. 결과 해석
4.1 특성 중요도(Permutation Importance, 순열 중요도)

완성된 모델이 판단하기에 정기예금 가입 여부에 큰 영향을 주는 특성은 무엇이었는지를 알아보기 위해 Permutation Importance를 구해보았다. 상위 3개의 특성이 분류결과에 영향을 많이 주는 것을 알 수 있었고 PDP 를 그려서 특성이 어떤 영향을 주었는지를 파악해보기로 하였다.
4.2 PDP(Partial Dependence plot, 부분 의존성 그림)

capaign은 마케팅 캠페인 중에 고객에게 연락한 횟수에 대한 특성이다. 캠페인 기간중에 연락을 한 횟수가 늘어날수록 0(정기예금 가입 안함)으로 예측한다고 해석할 수 있다.

다음은 순열중요도에서 상위 두가지, campaign, nr.employed 특성과 동시에 타겟과의 관계를 살펴보았다. 캠페인 기간중에 연락을 한 횟수 2회까지는 소폭 1로 예측할 확률이 상승하지만 이후부터는 횟수가 늘어날수록 0(정기예금 가입 안함)으로 예측한다고 해석할 수 있다. 연락을 적게할수록 직원숫자가 적을수록, 직원 숫자가 적을수록 정기예금에 가입할 확률이 높다고 해석할 수 있다. 해당특성을 pdp로 살펴보기 전에는 연락을 적게 할수록 정기예금 가입을 하지 않는다고 생각했는데 오히려 연락횟수가 적을수록 정기예금을 가입하는 경우가 많은 것으로 보인다. 연락횟수 1에서 2로 올라갈때는 소폭 증가하는 것을 보면 2회 이상 연락하는 것은 오히려 역효과를 내는 것으로 볼 수 있다.
5. 결론
5.1 Model의 기대효과 및 한계
미흡하게 만들어진 모델이지만 우리나라의 여건에 적용시킬 수 있을지 여부를 생각해봤을 때, 유리보(유럽연합 내 12개국 시중은행간 금리)등의 특성은 해당지역의 고유적인 인덱스이므로 그에 상응하는 우리나라의 고유지표를 찾아야 모델을 구축할 수 있을 것이며 바뀐 특성에 따라 성능도 물론 달라질 것이다. 하지만 우리나라의 특징에 맞는 특성들을 잘 교체할 수 있다면 충분히 모델을 구축할 수 있고 최적화여부에 따라 좋은 성능을 낼 수 있을 것 같다.
모델을 튜닝하며 성능을 개선하는 작업 자체는 성취감도 있고 굉장히 재밌다고 생각했는데 어떻게 성능을 개선해야겠다는 아이디어는 비교적 잘 떠오르는데에 비해 그것을 적용시키는데에는 무수한 오류를 헤쳐나가야 했기때문에 생각했던 모든 아이디어들을 시험해보지 못한 것들이 아쉬웠다.